Is D slim yet?
This is my project for last week’s D hackathon:
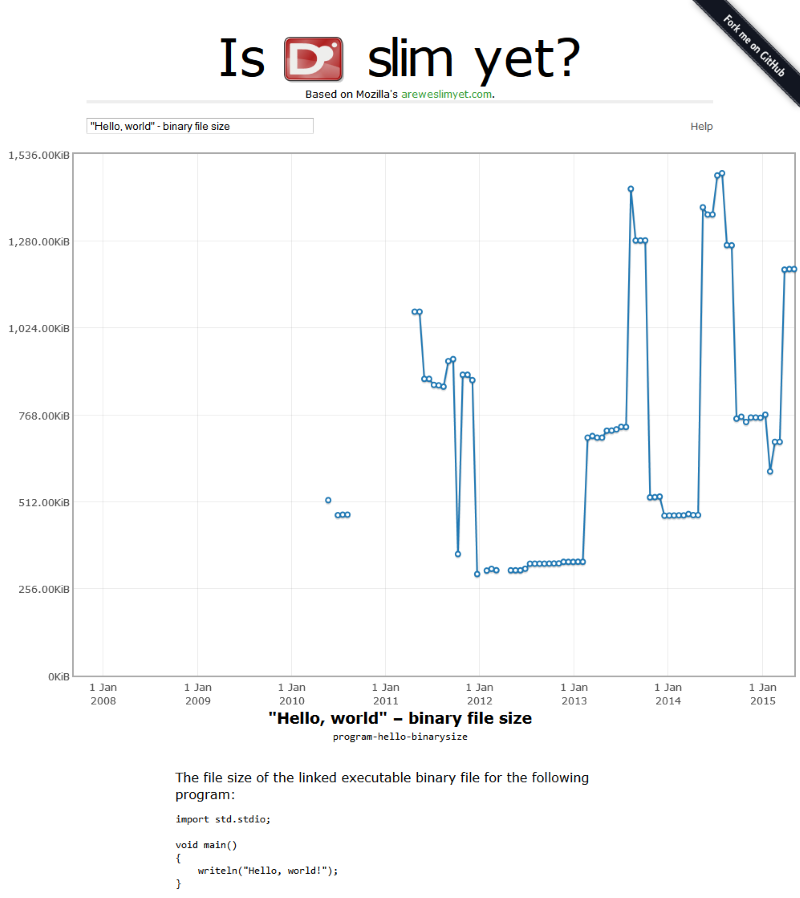
This project aims to visualize the evolution of D’s reference implementation across a number of metrics over time. It does this by building D at all points in its GitHub history, then running a series of measurements on each version.
The project brings together a number of components:
- Mozilla’s areweslimyet.com, which tracks Firefox memory usage in a similar way;
- D-dot-git, which generates a Git repository with a linear history from D’s components’ GitHub repositories;
- Digger, my D archaeology tool;
- ae.sys.d, the reusable library part of Digger;
- Git, in more than one way;
- TrenD ties them all together.
I thought I could knock this out in two days, but a few interesting challenges presented themselves:
1. How do I build all versions of D from every point in its history without running out of disk space?
At the time of writing, there are 13868 commits in the meta-repository generated by D-dot-git. The total number of commits in all of D’s components’ repositories is higher, but we don’t care about all of them. Ultimately, we are interested in the total distinct set of source code versions that we can get by atomically cloning all components simultaneously, at all points in time. This means that all pull requests get treated as one commit (the merge), which suits us just fine – we aren’t interested in intermediate commits inside pull requests, which might not even be buildable, as the auto-tester only tests each pull request’s branch head. This also solves the problem of flattening the convoluted history of multiple Git repositories (per D component) into one linear history. (More on this in my 2014 DConf presentation.)
Currently, the compiler, runtime, standard library and the rdmd build tool, as built by Digger, all together weigh 77 MB. Multiplied by 13868, and even if you account for earlier versions being smaller, that’s still more disk space than I wanted to allocate for this project. Of course, I could just not cache every single built D version, but that meant that adding a new benchmark would require building every version of D all over again, so I was looking to trade some disk space to save time.
Digger’s existing approach of minimizing disk space is using hard links: whenever a new build is cached, its neighbors (builds of the time-wise next/previous version, as well as builds from the same version but other build parameters) are scanned, and identical files are replaced with hard links. This saves some space, but not as much as I hoped: the biggest files were the binary ones, and small changes in the compiler or standard library caused the entire file to change.
My next experiment was with btrfs’ block-level deduplication. This did not go well. Lack of online deduplication does not sit well with mounting a sparse file as a loop device: you have to periodically stop the process filling up the disk to run the offline deduplication tool, as I found no simple way to reclaim disk space used by a sparse file hosting a btrfs partition after a deduplication run. Still, the space savings were not spectacular – I assume due to most changes inserting or deleting bytes, causing block-level mismatches in all data after the change.
I was considering simply compressing individual builds. They compress well (tenfold), which would’ve saved 90% of space, but this still seemed very wasteful, as there is so much duplicate data between builds. I wanted to try one more idea, using a well-known program that’s famous for its ability to handle duplicate data well, which is unsurprising because it was designed for this. The program is often used for backups, but most commonly is used for revision control. Yes, I’m talking about Git, of course.
The results were spectacular: 8x just from putting the files in Git, and a whopping 65x after a repack! This puts D’s fully-built history at a comfortable 5GB. And what’s curious, Git isn’t picky about the order in which you add files to the repository, which means that we can build D commits out of order without worrying that this will inflate the cache.
2. What’s a good order to run tests in?
Although we could just start with the oldest buildable version of D and benchmark each successive version, this wouldn’t be very efficient – it would take a lot of time to get to test all versions up to the latest, and adding a new benchmark would restart the whole process.
We can do better. I wrote a function which attempts to score each commit using a balance of curiosity and laziness, in the following way:
- Prefer recent commits
- Prefer commits with cached builds
- Prefer commits which are round numbers in base 2
- Prefer commits without test results
- Prefer commits between big differences in test results
Each rule grants a number of points which are added up. Rule #3 allows quickly getting an overview for new tests: it would put a big preference on commit number 8192, then on numbers 4096 and 12288, and so on.
Rule #5 is the most interesting one: if the algorithm sees two test results with a big difference next to each other, it will pick a commit between them, and assign to it a number of points proportional to the difference between the results. In effect, this causes the algorithm to automatically narrow down on (bisect, if you will) the commit or pull request that caused the spike in the results.
3. How to measure deterministically and precisely how much memory a program is allocating?
Answer: Use massif.
The source code is available on GitHub here, or you can play with the live version here (note the test selection drop-down).